|
I am currently a 4th-year PhD candidate at Shanghai Jiao Tong University (SJTU), fortunately advised by Prof. Weidi Xie and Prof. Ya Zhang. Before that, I received my B.S. degree in EE (IEEE Pilot Class) also from SJTU in 2022. I am generally interested in multi-modal learning, especially generative models, spatial intelligence, and AI4Sports. My ultimate goal is to build an artificial general intelligence that surpasses humans in perception, thinking, and practical abilities. I am always eager to communicate and cooperate, so feel free to contact me!!! By the way, I am currently open to research internship opportunities related to multi-modal generation and understanding. Feel free to connect via email or WeChat. Email: haoningwu3639 at gmail.com WeChat: haoningwu_ |

|
|
|
* denotes equal contribution, and † denotes corresponding author. |

|
Haoning Wu*, Xiao Huang*, Yaohui Chen, Ya Zhang, Yanfeng Wang†, Weidi Xie† CVPR, 2026. (NEW) project page / arXiv / code In this work, we investigate a critical question: to what extent do existing MLLMs possess spatial intelligence, encompassing both spatial perception and spatial understanding? |
|
Haolin Yang, Jiayuan Rao, Haoning Wu, Weidi Xie† CVPR, 2026. (NEW) project page / arXiv / code In this work, we present SoccerMaster, the first soccer-specific vision foundation model that unifies diverse understanding tasks within a single framework. |

|
Yanxu Meng*, Haoning Wu*, Ya Zhang, Weidi Xie† 3DV, 2026. (NEW) project page / arXiv / code In this work, we propose a feedforward 3D scene generation model that can simultaneously synthesize multiple 3D assets from a single image. |
|
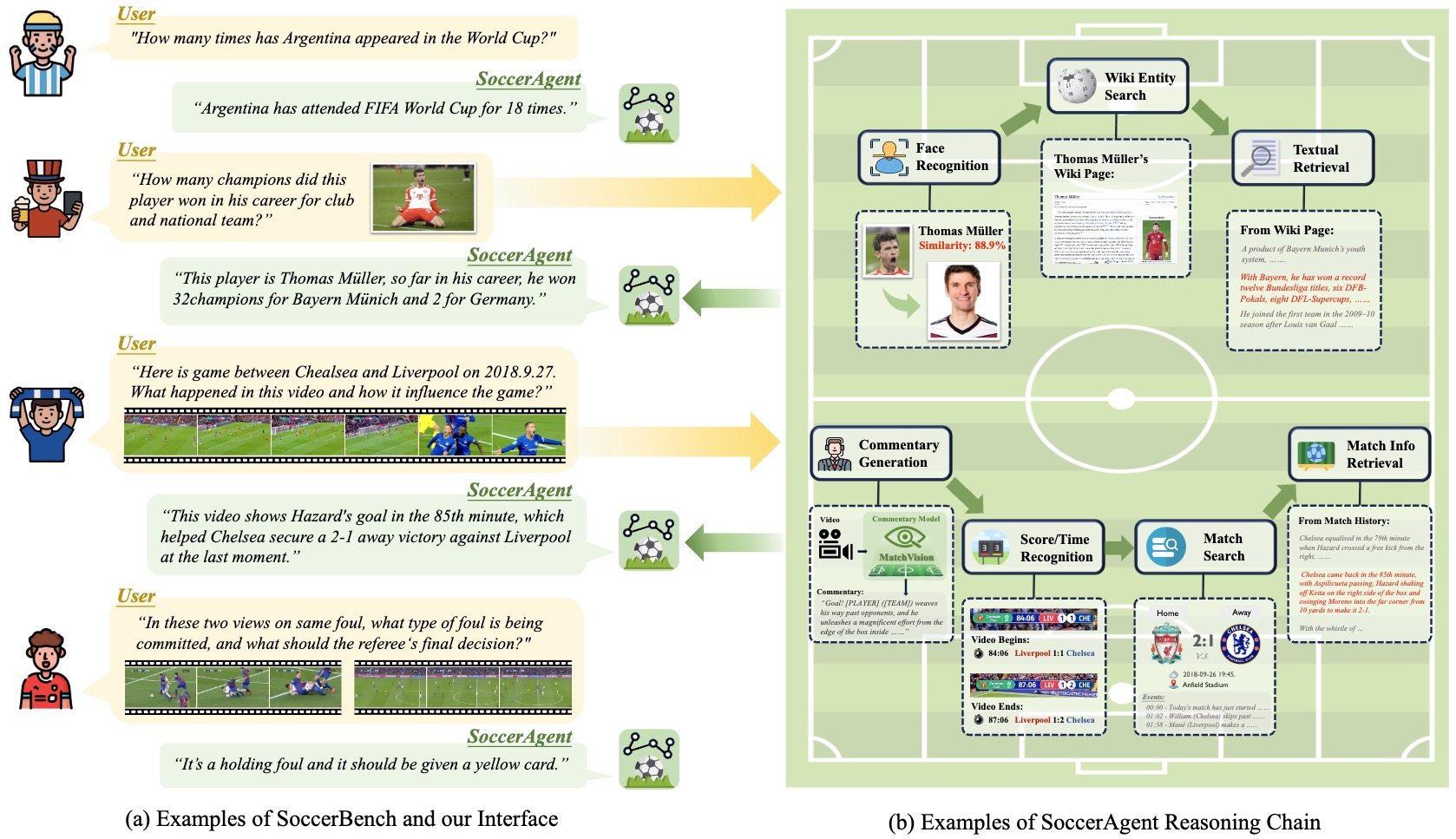
Jiayuan Rao*, Zifeng Li*, Haoning Wu, Ya Zhang, Yanfeng Wang†, Weidi Xie† ACM Multimedia, 2025. (NEW) project page / arXiv / code In this work, we present SoccerBench, the largest and most comprehensive soccer-specific benchmark, along with a multi-agent system, SoccerAgent, for soccer understanding. |
|
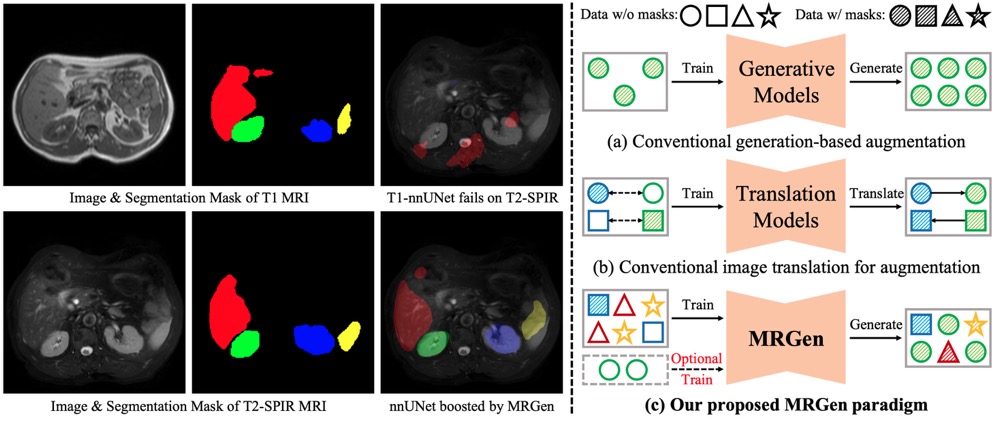
Haoning Wu*, Ziheng Zhao*, Ya Zhang, Yanfeng Wang†, Weidi Xie† ICCV, 2025. (NEW) project page / arXiv / code In this work, we establish a novel paradigm for generative models in medical applications: controllably synthesizing data for underrepresented modalities. |
|
Jiayuan Rao*, Haoning Wu*, Hao Jiang, Ya Zhang, Yanfeng Wang†, Weidi Xie† CVPR, 2025. project page / arXiv / code In this work, we present the first visual-language foundation model tailored for soccer video understanding, which can be applied various downstream tasks. |

|
Haoning Wu*, Shaocheng Shen*, Qiang Hu, Xiaoyun Zhang†, Ya Zhang, Yanfeng Wang WACV, 2025. project page / arXiv / code In this work, we propose a tuning-free strategy to extend the higher-resolution image generation capabilities of existing diffusion models. |
|
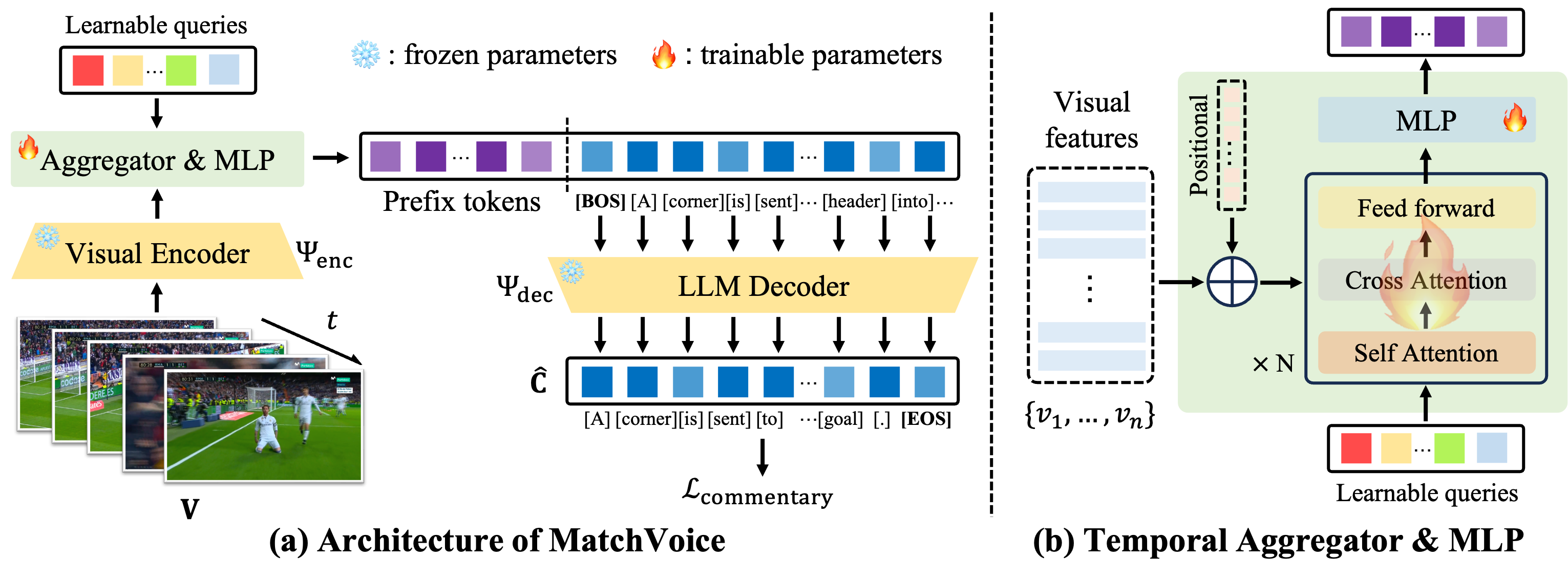
Jiayuan Rao*, Haoning Wu*, Chang Liu, Yanfeng Wang†, Weidi Xie† EMNLP, 2024. (Oral Presentation) project page / arXiv / code In this work, we focus on building an visual-language model for automatic soccer game commentary generation. |

|
Chang Liu*, Haoning Wu*, Yujie Zhong, Xiaoyun Zhang, Yanfeng Wang†, Weidi Xie† CVPR, 2024. project page / arXiv / code In this work, we focus on the task of generating a series of coherent image sequence based on a given storyline, denoted as open-ended visual storytelling. |

|
Qiuwen Wang, Shuai Guo, Haoning Wu, Rong Xie, Li Song†, Wenjun Zhang ACM Multimedia Asia, 2023. (Oral Presentation) paper / code In this work, we propose a novel framework, termed as NeRF-SDP, to address the challenge of balancing rendering speed and quality in generalizable NeRF. |
|
Haoning Wu, Xiaoyun Zhang†, Weidi Xie, Ya Zhang, Yanfeng Wang† BMVC, 2023. (Oral Presentation) project page / arXiv / code In this work, we propose a novel optimization-based VFI method that can adapt to unseen motions at test time and boost existing pre-trained models. |
|
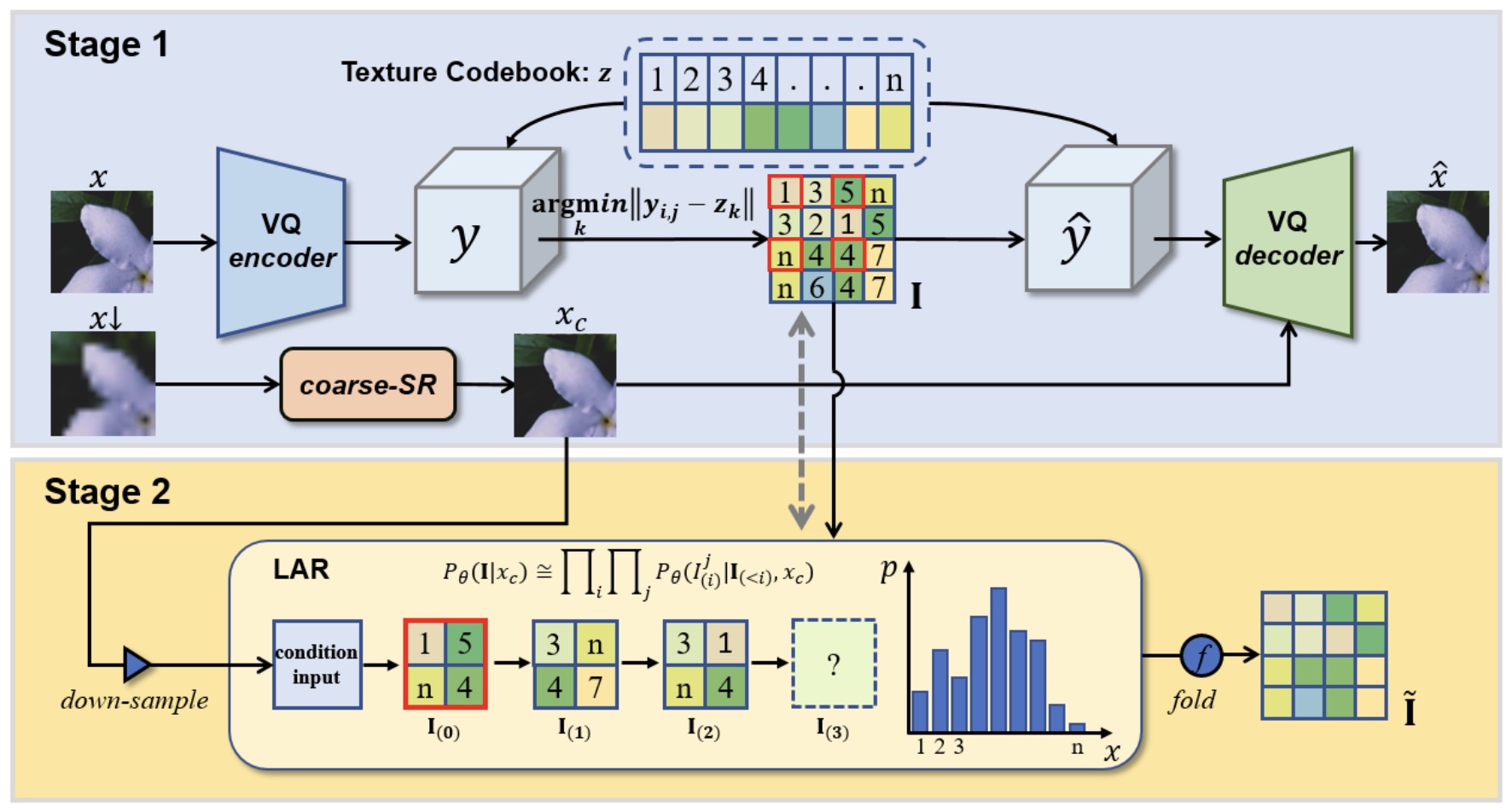
Baisong Guo*, Xiaoyun Zhang*†, Haoning Wu, Yu Wang, Ya Zhang, Yanfeng Wang† CVPR, 2022. paper / code In this work, we propose LAR-SR for super-resolution based on a Local AutoRegessive module, achieving superior performance among generative models for SR. |
|
|
|
|
|
|
|
Updated in February. 2026 Thanks Jon Barron for this amazing website template. |